Overview
The HPC Cluster Elysium is the central HPC facility of Ruhr-Universität Bochum. Its main governing structure is the HPC Advisory Board.
Other options include HPC centres in NRW and elsewhere.
The HPC Cluster Elysium is the central HPC facility of Ruhr-Universität Bochum. Its main governing structure is the HPC Advisory Board.
Other options include HPC centres in NRW and elsewhere.
The HPC@RUB cluster Elysium is operated by the HPC team at IT.SERVICES.
The governing structure of HPC@RUB is defined in the Terms of Use.
The HPC Advisory Board consists of five elected RUB scientists and two IT.SERVICES employees.
The five members of the current HPC Advisory Board, elected on April 18 2024, are:
The FairShare is a percentage that determines how much of the resources is available to a given facility on average. A facility with a 10% FairShare can use 10% of the cluster 24/7 on average. If it uses less, others can make use of the free resources, and the priority of the facility to get the next job to run on the cluster will grow. If it uses more (because others don’t make full use of their FairShare), its priority will shrink accordingly. FairShare usage tracking decays over time, so that it is not possible to save up FairShare for nine months and then occupy the full cluster for a full month.
Within a given facility, all scientists that are HPC project managers share its FairShare. All HPC projects share the FairShare of their manager. Finally, all HPC users share the FairShare of their assigned project. This results in the FairShare tree that has become the standard way of managing HPC resources.
HPC resources are managed based on projects to which individual users are assigned. The purpose of the projects is to keep an account of resource usage based on the FairShare of project managers within the FairShare of their facility.
Professors and group leaders can apply to become project managers; see the Terms of Use for details.
A project manager may apply for projects, and is responsible for compliance with all rules and regulations. Projects will be granted after a basic plausibility check; there is no review process, and access to resources is granted solely based on the FairShare principle, not based on competing project applications.
Users need to apply for access to the system, but access is only active if the user is currently assigned to at least one active project by a project manager.
| Type | Count | CPU | Memory | Local Usable NVMe Storage | GPU |
|---|---|---|---|---|---|
| Thin-CPU | 284 | 2xAMD EPYC 9254 (24 core) | 384 GB | 810 GB | - |
| Fat-CPU | 13 | 2xAMD EPYC 9454 (48 core) | 2304 GB | 1620 GB | - |
| Thin-GPU | 20 | 2xAMD EPYC 9254 (24 core) | 384 GB | 1620 GB | 3xNVIDIA A30 Tensor Core GPU 24GB, 933GB/s |
| Fat-GPU | 7 | 2xAMD EPYC 9454 (48 core) | 1152 GB | 14000 GB | 8xNVIDIA H100 SXM5 GPUs 80GB, 3.35TB/s, connected via NVLink |
To allow for high data transfer rates and low latencies all nodes and servers of Elysium are connected via a Cornelis Omni-Path network. The network topology is a 1:2 blocking fat-tree. Each node is equipped with a single-port Cornelis Omni-Path Express 100Gb/s adapter, except for the Fat-GPU nodes, which have four of these adapters. The Ping-Pong latency for a node-to-node communication with minimal hops is approximately 1.1 μs.
The following file systems are available:
/home: For your software and scripts.
High availability, but no backup.
Quota: 100 GB per user./lustre: Parallel file system to use for your jobs.
High availability, but no backup.
Not for long term storage. Quotas: 4.5 TB and 1,900,000 files per user./tmp: Fast storage on each node for temporary data.
Limited in space, except for FatGPU nodes where multiple TB are available.
Data is removed when the job ends.
For shared jobs the quota scales with the number of reserved cores.Two partitions are available for each type of compute node: the filler partitions are designed for short jobs, while the standard partitions support longer-running tasks.
Jobs in the filler partition have a lower priority and will only start if no job from the regular partition requests resources. Running jobs in the filler will cost only a fraction of the fair share of a regular partition.
The vis partition is special since the visualization nodes are intended for
interactive use only.
| Partition | Timelimit | Nodelist | Max Tasks per Node |
Max Memory per CPU³ | Share-Cost² |
|---|---|---|---|---|---|
| cpu | 2-00:00:00¹ | cpu[001-284] | 48 | 8 GB | 1.000 / core |
| cpu_filler | 3:00:00 | cpu[001-336] | 48 | 8 GB | 0.050 / core |
| fat_cpu | 2-00:00:00 | fatcpu[001-013] | 96 | 24 GB | 1.347 / core |
| fat_cpu_filler | 3:00:00 | fatcpu[001-013] | 96 | 24 GB | 0.067 / core |
| gpu | 2-00:00:00 | gpu[001-020] | 48 | 8 GB | 49.374 / GPU |
| gpu_filler | 1:00:00 | gpu[001-020] | 48 | 8 GB | 12.344 / GPU |
| fat_gpu | 2-00:00:00 | fatgpu[001-007] | 96 | 12 GB | 196.867 / GPU |
| fat_gpu_filler | 1:00:00 | fatgpu[001-007] | 96 | 12 GB | 49.217 / GPU |
| vis | 12:00:00 | vis[001-003] | 48 | 24 GB | 5.000 / core |
¹ Times of up to 7 days are possible on this partition but not recommended. Only 2 days are guaranteed, jobs running longer than that may get cancelled if that becomes necessary for important maintenance work.
² Cost does not refer to money, but the factor of computing time that is added to a projects used share in order to compute job priorities. The costs are based on the relative monetary costs of the underlying hardware.
³ Some of the memory is reserved for system services.
Please check the scontrol show partition <partition_name> command
to get the amount of memory that is available for your job
via the --mem-per-cpu=<mem> submission flag.
The HPC resources in Germany are arranged hierarchically in the so-called HPC pyramid.
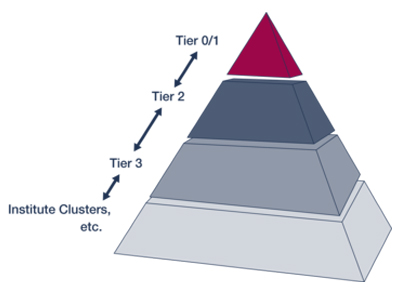
If suitable for your needs, use the local resources provided by the tier-3 centre. If you need more resources than the local centre can provide, or your project requires specialized hardware, you are welcome to contact another HPC centre or request computing time at a higher tier (tier-2 or tier-1).
Several state-wide tier-2 centres (NHR centres) are available to cater for specialized computing and/or storage requirements. In North Rhine-Westphalia, the RTWH Aachen, the University of Cologne and the University of Paderborn offer structured access to HPC users from NRW institutes.
For extremely complex and data-intensive requirements, HPC resources of the highest tier are available in Germany and the EU. Computing time is only allocated after a technical and scientific peer review process (GCS, PRACE).
We would be happy to advise you on the suitability of your projects as well as provide help with the application process for all levels of the HPC pyramid. Please contact us.
![]()
![]()
The Ruhr-University of Bochum is part of the North Rhine-Westphalian Competence Network for High Performance Computing HPC.nrw. This network offers a first point of contact and central advisory hub with a broad knowledge base for HPC users in NRW. In addition, the tier-2 centres offer uniform, structured access for HPC users of all universities in NRW, ensuring basic services are provided for locations without tier-3 centres and for Universities of Applied Sciences.
A network of thematic clusters for low-threshold training, consulting and coaching services has been created within the framework of HPC.nrw. The aim is to make effective and efficient use of high-performance computing and storage facilities and to support scientific researchers of all levels. The existing resources and services that the state has to offer are also presented in a transparent way.
According to the Terms of Use, publications must contain an acknowledgement if HPC resources were used. For example:
“Calculations (or parts of them) for this publication were performed on the HPC cluster Elysium of the Ruhr University Bochum, subsidised by the DFG (INST 213/1055-1).”
The RUB University Library helps us maintain a list of such publications, updated in regular intervals: